Tekton is groovy...
Lets not upset anyone, Tekton doesn't use "Groovy" as its configuration language (thankfully). Tekton is groovy in its own right however. I believe Ash said it best:

Short History of CI/CD Tooling
For those that don't understand what Groovy is (the syntax used for Jenkins Pipelines), I'm happy for you. For those who don't know the person or the film the above image is from, please stop whatever it is you are doing (including reading this) and go watch Army of Darkness.
Before we dive into Tekton, let's take a quick look at "the big one" that has been used for many years now, Jenkins. Sure there are other tools out there that have been used over the years, but Jenkins has probably been the biggest one and had the widest use for the longest time. So what is Jenkins? Jenkins is an open-source "automation server", which really translates to a platform based on Java that is extensible with many plugins to do numerous things. It could be run anywhere and years ago would have many VMs dedicated to running large instances for an organization, or you could have it running in your Kubernetes cluster in containers.
One of the things that made Jenkins popular was a platform that was "extensible", but allowed you to have a someone custom execution environment. For the most part it was basically the ability to run shell commands with some plugins that took arguments. Here is a brief example of what a Jenkins pipeline would look like to build and deploy a new application:
pipeline {
agent any
stages {
stage('Build') {
steps {
sh 'make'
}
}
stage('Test'){
steps {
sh 'make check'
junit 'reports/**/*.xml'
}
}
stage('Deploy') {
steps {
sh 'make publish'
}
}
}
}As you can see from above, its somewhat logically laid out and clearly defines each stage of the pipeline. You may notice though that this basic pipeline is essentially running shell commands and nothing really special. The agent line up above specifies which "instance" to run on. One of the great things about this is you could have certain agents that had different tooling and were lighter weight. The big thing here I want to point out is the syntax of Groovy, which looks like JSON. Nothing is wrong with JSON except for the humans having to write it. Just to be clear, you can technically get this out of the Jenkins UI, but that isn't very declarative or repeatable, so we're going to focus on the manifest pipelines like above.
JSON style formatting is great for machines, but for humans it isn't exactly easy to read/write. Now the above is somewhat easy, but its only 1-2 line objects for each stage. As this would grow, or having other types of components in the various stages, the above would go from somewhat readable to a large collection of curly braces. Here is roughly the same pipeline, but in Tekton format:
apiVersion: tekton.dev/v1beta1
kind: Pipeline
metadata:
name: my-pipeline
spec:
workspaces:
- name: shared-dir
tasks:
- name: build
taskRef:
name: app-build
workspaces:
- name: source
workspace: shared-dir
- name: test
taskRef:
name: app-test
workspaces:
- name: source
workspace: shared-dir
- name: deploy
taskRef:
name: app-deploy
workspaces:
- name: source
workspace: shared-dirNOTE: I want to call out in the above is that it is 5 lines longer than the Jenkins pipeline and you are getting technically the same pipeline of tasks in the end.
For those who are familiar with Kubernetes manifests (and I hope you are at least somewhat, since we are looking at a tool/platform for Kubernetes), you will notice that the Tekton example above is just that, a Kubernetes manifest whereas the Jenkins file further above is "its own thing". Tekton itself is a "cloud-native" platform (aka Kubernetes native) that installs and becomes an extension of the Kubernetes cluster itself. The huge benefit here on its own over Jenkins is that, you can use your existing tools to work with Tekton since its "in cluster" and native.
Enough looking at Jenkins compared to Tekton, let's actually start digging into Tekton itself. If you do not understand the Tekton Pipeline example above, fear not, we will be doing a deep dive on that very shortly. For all examples (except the pseudo-code here and there) the manifests can all be found in the supporting repository for this post:
 KyWa
KyWaA Brief overview of Tekton
If you are familiar with Ansible (this is not a CI/CD tool, although some try to use it for that purpose), there are some super easy comparisons to make so you can grasp the components of Tekton quite easily:
A lot of the components of Tekton can easily be translated to Ansible items (and almost easily to Jenkins items). For those who are unfamiliar with Ansible, then this is a great little listing of some of the components of Ansible. I do also have a primer written for Ansible in a previous post during the MineOps series that can be read if you are curious about Ansible.
| Tekton | Jenkins | Ansible | Description |
|---|---|---|---|
Task / ClusterTask |
stage in Jenkinsfile |
task |
Definition of "what to do" |
TaskRun |
N/A |
ansible -m shell |
Execute a Task |
Pipeline |
Jenkinsfile |
playbook.yml |
A collection of Tasks |
PipelineRun |
Jenkins UI or CLI | ansible-playbook playbook.yml |
Executes a Pipeline |
I try to make the comparison to Ansible due to the nature of how Tekton works as its very "Ansible-esque". You put your tasks with their parameters and send them off to do whatever it is you want. Ansible has the ability to only run certain tasks "when" something occurs or if a certain variable is set, but they are run in order from top down through the playbook or "pipeline". In Tekton you also get a when field, which functions exactly like you would expect, but you also get a different field you can add, runAfter. This allows you to run certain tasks only after others have run. Most devs will probably build out their Pipelines in order top down, but it does give you the ability to only run certain tasks after others have run (such as a test cant be run until the build has been run).
Tekton Component: Task
Let's take a look at what a Tekton Task looks like so we can better understand what a Pipeline is and how it works.
---
apiVersion: tekton.dev/v1beta1
kind: Task
metadata:
name: basic-task
spec:
params:
- name: URL
type: string
description: "What URL you wish to curl"
steps:
- name: curl-something
image: someimage:tag
command:
- curl
- $(params.URL)In the above manifests, we have very few fields, but they are all very self explanatory. No need to explain anything outside of the spec field except that the apiVersion will most likely eventually update to no longer be a v1beta1 endpoint, so just keep that in mind.
A breakdown of what we have in the Task is fairly straightforward as this is a very basic Task. Let's cover the fields we have and what they do:
params- This is where parameters for theTaskcan be specified as far as what it can make use of. You must specify at least thenameandtypefields, but you can also specify adescriptionanddefaultfield. Thedefaultfield is where you can specify a default value if none are provided when theTaskis run (either from aPipelineRunorTaskRun, but more on this later)steps- Determines the steps the task needs to take to complete. A note here, aTaskcan have many steps and each step is a container in the Pod that is created for theTasksteps.name- This names the step in the Task. In the above example the container name would bestep-curl-somethingsteps.image- Which container image to use for thisTask(we will explore this a little bit more)steps.command- Just like a container manifest you specify what command to execute when the container starts up, or in this case the step. You could also usescriptinstead ofcommand, but again, more on this later just know that neither is required as the image may have its own command you want to use
One of the unique things you may have noticed is in the command arguments a very "variable" looking line that shows $(params.URL). This is one of the components of Tekton that allows you to pass in parameters to the Task and not even just lines in the command field, you can also use this for the image line and others. Tekton has a webhook that validates all of the objects passed in prior to creating the Task. This gives you the ability to "templatize" your Kubernetes manifests (at least Tekton manifests) by having some fields be dynamic. One unique way to utilize this feature is by having the image line(s) of a Tasks step(s) have a tag that is specified by a parameter. An example of this, would be having a Task which does "something" for you, but could be re-used for a different purpose if a different image/tag was used (maybe testing different versions of NodeJS). You can keep the same Task with the same test logic, but you can have the image used be different when you run it depending on the NodeJS version you are looking to test.
There is no way we can go over all of the specifications for a Tekton Task in this post, but here are 2 resources that may help for a more detailed dive into the components of a Tekton Task:
Tekton Component: TaskRun
A TaskRun is just what it sounds like, it runs a Task. Thankfully it doesn't get much more straight forward than this, so lets take a look at what a TaskRun looks like to run our simple curl task above:
---
apiVersion: tekton.dev/v1beta1
kind: TaskRun
metadata:
name: basic-task-run
spec:
params:
- name: URL
value: https://github.com
taskRef:
kind: Task
name: basic-taskThe TaskRun looks very similar to our Task (being how basic and minimalistic it is) and we can see it has a params spec just like a Task does. The params field(s) here are used to "pass" values to a Task that is being run through the TaskRun object. If a TaskRun is created without having all the params required by the Task that do not have default values set, the TaskRun will fail due to missing `params. It is important to know the Tasks you are attempting to run, although that should go without saying.
Since we mentioned having your Kubernetes manifest templatized, it would be important to point out you can use a podTemplate in a TaskRun (and PipelineRun) objects allowing you even finer control. This gives you the ability to call out specific things such as a dnsConfig or other Pod specific fields you cannot add to a Task. We wont really get into that, but its important
Tekton Component: Pipeline
Pipelines are what make Tekton fun to use as you don't have to declare how you want all of the Tasks to run and in what order. A Pipeline can be described by the following:
- A collection of
Tasksto be run - The order in which said
Tasksrun - What parameters it provides to the
Taskswhen they are run
I said the word "run" quite a bit there, that is because everything in Tekton has to be "run" in some capacity (with the "technical" exception of Triggers).
A Pipeline looks very similar to a Task in its structure, but is typically "trimmed" down somewhat in comparison. Unlike Tasks however, a Pipeline doesn't necessarily run through its list of Tasks serially. Below we have an example Pipeline to run our basic-task to curl:
---
apiVersion: tekton.dev/v1beta1
kind: Pipeline
metadata:
name: basic-pipeline
spec:
params:
- name: URL
type: string
description: Which URL to curl
tasks:
- name: get-url
taskRef:
name: basic-task
params:
- name: URL
value: $(params.URL)Now some of this may look like a "duplication" of what is in the Task and you'd be right to say that at first glance. A single Task and a Pipeline really don't mix as Pipelines are meant to be a compilation of Tasks, so at first glance you seem to have duplicates of parameters. In reality you are specifying what parameters a Pipeline accepts (similar to a Task), but these parameters can have their own names unique to the Pipeline. When you pass in a parameter to a Task in the tasks field of the Pipeline you will pass the parameter name the Task needs, but you can give it a predefined value, or as in the example above, give it a value equal to the Pipelines parameter. This is done through Tekton's variable substitution which looks like $(params.URL). We could change the Pipelines parameters to something completely different and as long as we tell the Task what its parameter is getting its value from, it doesn't matter what we call it. Although obviously it would be smart to keep the names somewhat relevant for the sanity of you and your team later down the road.
So let's look at the "final core" component of Tekton, the PipelineRun.
Tekton Component: PipelineRun
Much in the same as the relation of a Task and a TaskRun, so to is a Pipeline and a PipelineRun. There is one difference however in that a Pipeline doesn't get "run" in the same sense. A Pipeline is just a collection of Tasks so when a PipelineRun runs a Pipeline it is going to create the TaskRuns for those Tasks with only the Pipeline being a reference for the creation of these objects.
---
apiVersion: tekton.dev/v1beta1
kind: PipelineRun
metadata:
name: basic-pipeline-run
spec:
params:
- name: URL
value: https://github.com
pipelineRef:
name: basic-pipelineThe above is a PipelineRun for the Pipeline we are using for our example, basic-pipeline. What this manifest is going to do is generate TaskRuns from the tasks in the Pipeline after generating all the variables being set by the Pipeline and then passing them to the TaskRuns. The order of object creation from running a Pipeline looks like this:
Task <- Pipeline <- PipelineRun -> TaskRun
Remember that we said each TaskRun generates a Pod to do its "tasks" and each step is a Container in that Pod. This last bit is important when planning your Pipelines if you need to carry over "data" from one Task to another. This will be handled in a later section of this article for workspaces.
Installing Tekton
As with most "add-ons" to Kubernetes, Tekton can be installed very easily through a single command (assuming you have some level of cluster-admin privileges):
kubectl apply -f https://storage.googleapis.com/tekton-releases/pipeline/previous/v0.35.1/release.yaml
With that you will install all the components for Tekton to run in your cluster. After a few moments (or minutes depending on network speed), Tekton will be installed in your cluster. At the time of this writing, v0.35.1 is the latest release of Tekton so that is what we will be using. To look into other installation methods, the official Installation Documentation is your best place to look.
By default the above installs into the tekton-pipelines namespace, but you could modify the YAML manifest prior to applying it, but the default namespace should be fine for most teams so that is where we will work out of. In a vanilla install of Tekton, you really only get the controller and the validating webhook (which converts the Tekton manifests as stated previously). There are no Tasks, ClusterTasks or Pipelines for you to utilize out of the box. There are a few ways (outside of creating your own) to get some base Tasks in your cluster. One of those is by using the Tekton CLI, tkn. The CLI is not required for use with Tekton, but does make some things easier such as installing Tasks from Tekton Hub.
Tekton CLI Install
Installing the CLI is OS dependent and there are even other ways outside of the usual "install the binary" for tkn (the CLI for Tekton). You can technically make it a plugin for kubectl if you choose, but that is outside the scope of this article. For OS specific information, check the official Tekton CLI documentation. I've already got tkn installed (via brew) so let's see the above in action.
Installing Tasks from Tekton Hub

tkn install task from Tekton HubThe commands run above were:
tkn hub install task git-clone -n tekton-is-groovy
kubectl get task -n tekton-is-groovyAnd now we have the git-clone Task in our namespace so we can make use of it later (which we will). The -n is not necessary, but does make it easier to install Tasks to a specific namespace.
Installing Tekton Tasks without tkn
The above can also be done without the tkn CLI utility by running:
kubectl apply -f https://raw.githubusercontent.com/tektoncd/catalog/main/task/git-clone/0.6/git-clone.yamlAs stated before, tkn isn't required to do anything, but when getting started or just testing things quickly, it can make life a little easier. We won't be diving into tkn too much, but for some of our initial Task and Pipeline testing we will use it here and there. We will also be looking at YAML manifest equivalent's of the tkn commands just for comparison sake. Obviously if you are going to have CronJobs or some sort of "runner" handle your Tekton runs, then the CLI may make sense to make available to a runner. The choice is up to you and your team in how you want to make use of Tekton.
Real World Tekton Usage
What we've gone over so far has been pretty basic, so basic in fact, the name of our objects all start with basic (a terrible joke I know). We haven't even scratched the surface of what makes Tekton a great CI/CD tool. Before we dive into some of the cooler features, lets look at some Tasks and a Pipeline that do a little bit more than curl a URL. Let's setup a common pipeline to build and rollout an application.
Build and Rollout
For those who are unaware, you can build container images on Kubernetes. If you are familiar with Red Hat OpenShift (or its upstream project OKD), then you've most likely already been using the BuildConfig object's and this will be nothing new. What about those who are using a vanilla Kubernetes cluster and don't have the BuildConfig object in their cluster? Who would even need to build an image on Kubernetes when you can just run Docker locally? Well obviously, your organization isn't going to use your laptop for its pipeline's (hopefully that isn't the case), but also more importantly, there are organizations where you aren't allowed "normal" developer tooling on your machine for "security" reasons. Whatever the case, let's look at building a container image with Tekton.
NOTE: Tekton itself does not possess any magical ability to build Container images. We are just using Tekton to do things you could normally do in Kubernetes, but inside of a Tekton Task and Pipeline. Many have used "Docker in Docker" in their CI/CD pipelines over the years to accomplish this, but still is foreign to many people I've met and talked with over the years.
Building a Container Image in a Container
The above may sound silly and redundant, but its extremely powerful and important for modern CI/CD pipelines. Since everyone has an executive who say "We need Kubernetes now!", obviously you are dealing with containers whether you want to or not (I'm kidding of course). And because of that, you should try to use tooling that is native to whatever platform you are running on (which I hope is Kubernetes if you're reading this article). "Docker in Docker", or dind for short, is something that has been around for years at this point, but as with most things, there are different options and arguably better tools to use for some tasks. Enter Buildah.
Buildah is a project managed by the Containers organization and unlike docker (the application) it seeks to focus on one core task as opposed to "everything" involved with containers. Buildah has many features that expound upon building container images that are OCI compliant and will run in a "Docker" environment. We are not going to go into a deep dive of Buildah here, but we are going to use Buildah to build our container image. To build a container image with Buildah, the flags are very similar to how you would build an image with docker or podman:
# Docker
docker build -f Dockerfile -t quay.io/your-repo/some-image:tag
# Buildah
buildah build -f Dockerfile -t quay.io/your-repo/some-image:tagHistorically docker only looked for a file called Dockerfile when running a build, but this is no longer the case these days (thankfully). Tools like buildah and podman allow you to make use of any file as long as it is in the traditional Dockerfile format and since their inception. A Task to use buildah looks pretty straight forward and we will use the script field as opposed to command as it gives us slightly better control over the step in our Task:
steps:
- name: build
image: quay.io/containers/buildah
workingDir: $(workspaces.builder.path)
securityContext:
privileged: true
script: |
#!/usr/bin/env bash
buildah --storage-driver=overlay build --no-cache -f $(params.DOCKERFILE_PATH) -t $(params.REGISTRY)/$(params.REPOSITORY)/$(params.IMAGE):$(params.IMAGE_TAG) .
volumeMounts:
- name: varlibcontainers
mountPath: /var/lib/containersIts pretty straight forward, but the core things here is that our image we are building, we are going to name and tag with params for the Task (not shown, but you can see their names so that is all that really matters). There is a follow up task, which runs buildah push, which will push the image to the container registry that is specified through the params. One thing you may notice is the field that is granting the privileged securityContext. This is required to use parts of the filesystem that containers need to "run". There are ways to do this in a "rootless" or privilege-less environment, but for the scope of this we are going to focus on using this method.
We have a method of building a container image, but where is our Dockerfile going to come from? Typically this is going to be in a Git repository somewhere (or some other source control mechanism) and so long as its publicly reachable that is is all we need to do. So we need to pull down our source code along with the Dockerfile so the application can be built. If we follow best practices, we would have one Task acquire our source code, another handle the build and finally a task to rollout our application for testing (which would be its own task, but outside the scope of what we are looking at here). Since each Task is a new Pod, how is the Task that gets our source code going to make it available to our buildah Task? The typical obvious answer is a volume created through a PVC, but Tekton has something "better" that can be used. It's time to look at workspaces.
Workspaces
Tekton allows you to make use of workspaces, which as stated above can function just like a volume would in your Kubernetes Pods. When using a workspace it functions quite similarly to a volumeMount in how its used inside of a Task step, but you can have it be a dynamic path without needing to "hard code" the path inside of the container. Let's take a look at how you would use a workspace and then we will look at declaring one:
apiVersion:
kind: Task
metadata:
name: some-task
spec:
steps:
- name: persist-code
image: quay.io/example/someimage:latest
script: |
cat $(workspaces.mydir.path)/somefile.txt
workspaces:
- name: mydirThe Task above will run a very basic step that runs cat on somefile.txt which is in the workspace named mydir. The path in which that lives inside of the actual running container will be (by default) /workspaces/mydir. Obviously at the end of the day everything boils down to a mount path in the container, the one big bonus of using workspaces over a normal volumeMount is that you do not have to worry about where things are mounted. You can just use $(workspaces.NAME.path) and it will use the actual path in its place during the steps of your Task.
Something to remember with workspaces is that just like volumes this doesn't have to be a PersistentVolumeClaim, it could be anything you would normally mount to a container such as a Secret, ConfigMap or even an emptyDir. For each Task there may be different reasons to use one over the other, but the main benefit is that you don't have to specify a path for your steps and can just rely on the variables as shown above.
For actually declaring workspaces and how they work is quite simple and does give you some flexibility (again its almost exactly like a volume in the configuration):
workspaces:
- name: some-name
description: What goes here or lives here
mountPath: /some/alternative/mount
optional: true
readOnly: falseThe only field above that is mandatory is the name field, all else is optional. Now what this workspace is depends on how its mapped from a TaskRun or a PipelineRun (which creates a TaskRun for each Task in a Pipeline). You have quite a few options (again just like a volume):
workspaces:
- name: pvc-workspace
persistentVolumeClaim:
claimName: my-pvc
- name: volumeclaim-workspace
volumeClaimTemplate:
spec:
accessModes:
- ReadWriteMany
resources:
requests:
storage: 1Gi
- name: emptydir-workspace
emptyDir: {}
- name: secret-workspace
secret:
secretName: my-secret
- name: configmap-workspace
configMap:
name: some-configmapAbove is pretty much the options you could/would use with a Tekton workspace and for those who have used Kubernetes for some time, looks identical to what you would/could do with a volume. I keep bringing this comparison of volumes and workspaces to show they roughly the same with the main benefit of being more declarative with workspaces for your "pipelines" as a whole.
After all of that explanation, here is a quick tl;dr on volumes vs workspaces:

With that covered, let's see using workspaces in action.
I've created a simple Pipeline, which we will extend later to our complete build and rollout Pipeline, but for now we can use it to test the workspace feature for getting our source code and then building an image with it.
---
apiVersion: tekton.dev/v1beta1
kind: Pipeline
metadata:
name: build
spec:
workspaces:
- name: ssh-creds
- name: build
- name: registry-credentials
tasks:
- name: fetch-repository
taskRef:
name: git-clone
workspaces:
- name: ssh-directory
workspace: ssh-creds
- name: output
workspace: build
- name: build
taskRef:
name: buildah
runAfter:
- fetch-repository
workspaces:
- name: builder
workspace: build
- name: registry-secret
workspace: registry-credentialsFor ease of readability I took out the params to focus on the tasks and workspaces and how they all interact. The git-clone task (which we pulled in earlier through the tkn CLI) really only needs one workspace and that is output which is where the Git repository will be cloned into. If the repository is private however, you will need to provide credentials for the git-clone task to be able to pull from that repository. We will be using SSH based authentication, but this will be defined in the PipelineRun and only the ssh-directory workspace is needed for the task declaration in the Pipeline.
The buildah task we've created, which is based on this one from Tekton Hub, technically only needs a workspace that contains the code to build a container, but does require some form of credential for pushing the built image to a container registry. Let's see our PipelineRun to get some more clarity on how the workspace declaration works:
---
apiVersion: tekton.dev/v1beta1
kind: PipelineRun
metadata:
generateName: build-pipeline-run-
spec:
params:
- name: SOURCE_URL
value: git@github.com:KyWa/kywa-website.git
- name: IMAGE
value: "kywa-website"
- name: IMAGE_REGISTRY
value: docker.io
- name: IMAGE_REPOSITORY
value: mineops
- name: DOCKERFILE
value: "Dockerfile"
pipelineRef:
name: build
workspaces:
- name: ssh-creds
secret:
secretName: ssh-auth
items:
- key: ssh-privatekey
path: id_rsa
- name: build
volumeClaimTemplate:
spec:
accessModes:
- ReadWriteMany
resources:
requests:
storage: 2Gi
- name: registry-credentials
secret:
secretName: docker-hub
items:
- key: .dockerconfigjson
path: authThis Pipeline is being run with 3 total workspaces:
ssh-creds- This is a Kubernetes Secret which contains SSH credentialsbuild- AvolumeClaimTemplatewhich will request a PVC be created and used for source code storageregistry-credentials- Another Kubernetes Secret containing a.dockercfgfor the image registry credentials
Let's give it a run and see what it looks like:

Now that we see how we can build a container in a container, the last "task" would be to see about using this image we built to update an existing Kubernetes Deployment with the image digest for it to rollout. This Pipeline can be quite powerful as being able to handle automatic rollouts for a Deployment is a great start to getting towards a fully automated CI/CD pipeline.
Planning our Build and Rollout
This Pipeline is only adding a single task to what we just did previously with our buildah Pipeline. The manifests used for the "build and rollout" can be found in the supporting repository for this post.
Running our Build and Rollout
With our Pipeline defined, we can in theory actually go to run it with a PipelineRun object:

This is a very basic CI/CD pipeline, but could be easily (and should be) extended with another task after the deploy to run some tests and once that is done "prod" could be rolled out with that image on a successful test. Tekton really can do whatever you want it to without much effort. It all comes down to "how do you want to do it?".
Dashboard (BETA)
If you're tired of the terminal and wan't to see a GUI element, I have just one thing to say to you, let's see what the Tekton Dashboard looks like!. Didn't think I was going there did you? Although the terminal is the greatest place on Earth (sorry Disney, also not sorry), there are times when you just want to get some visibility outside of kubectl.
The Tekton Dashboard has some pretty nice features and is great for visibility. The project can be found in its GitHub repository and is installed much in the same way Tekton itself is, the trusty kubectl one-liner:

Much like with other "web" services running in Kubernetes, you will need some form of Ingress to access it. That is outside the scope of this tutorial, but was covered in a previous post during the MineOps series. Already having an Ingress setup for this cluster, we can now view the Dashboard. Again at the time of this writing, the Tekton Dashboard is still in "BETA", but it is quite feature rich and can do pretty much all the things you'd expect it to do (view and run Pipelines!):
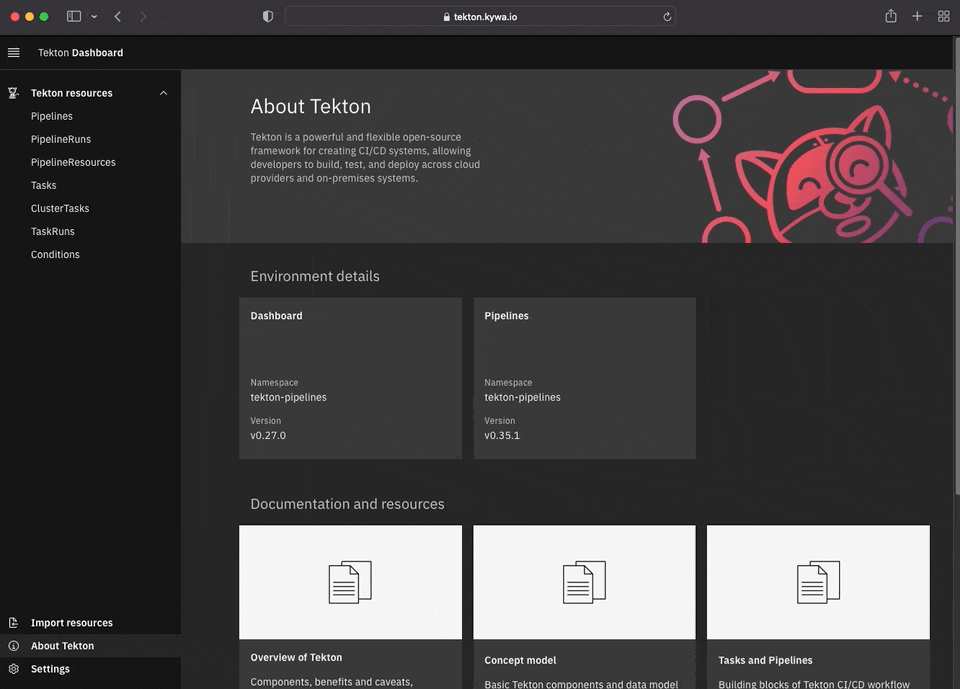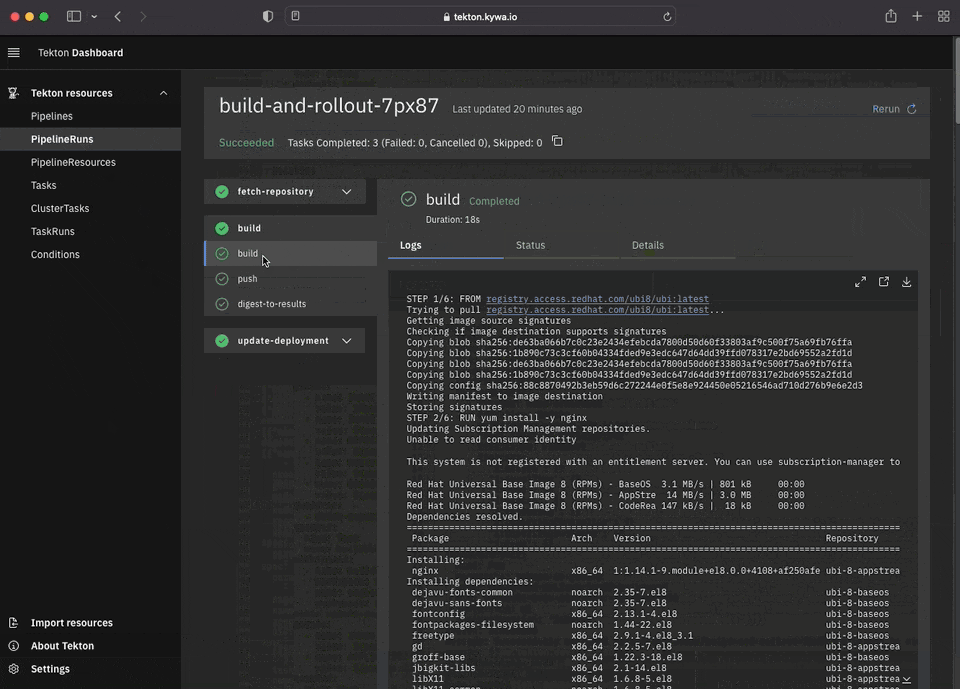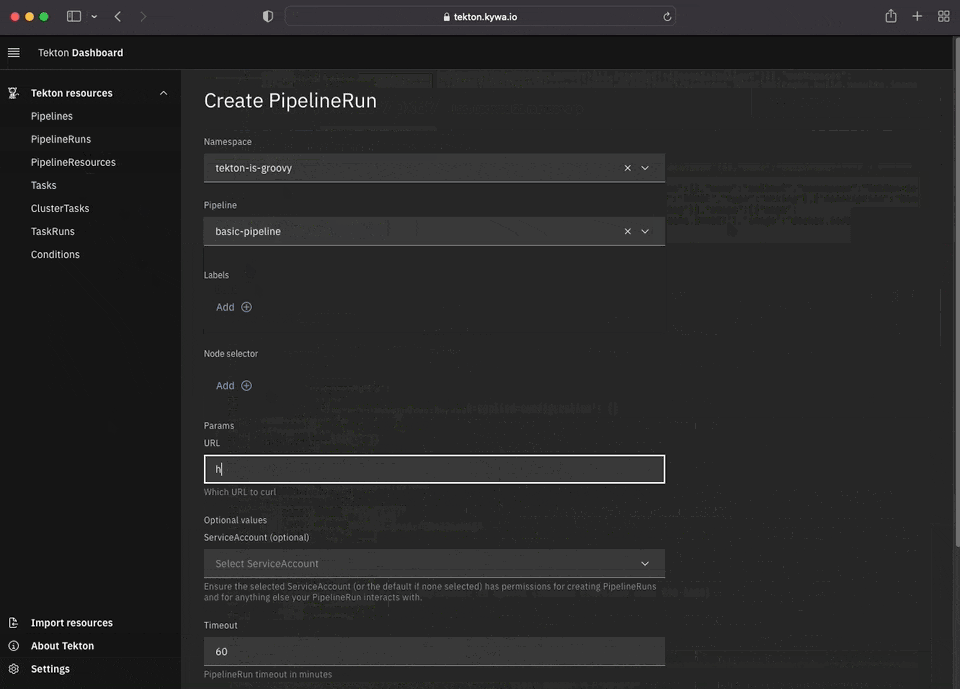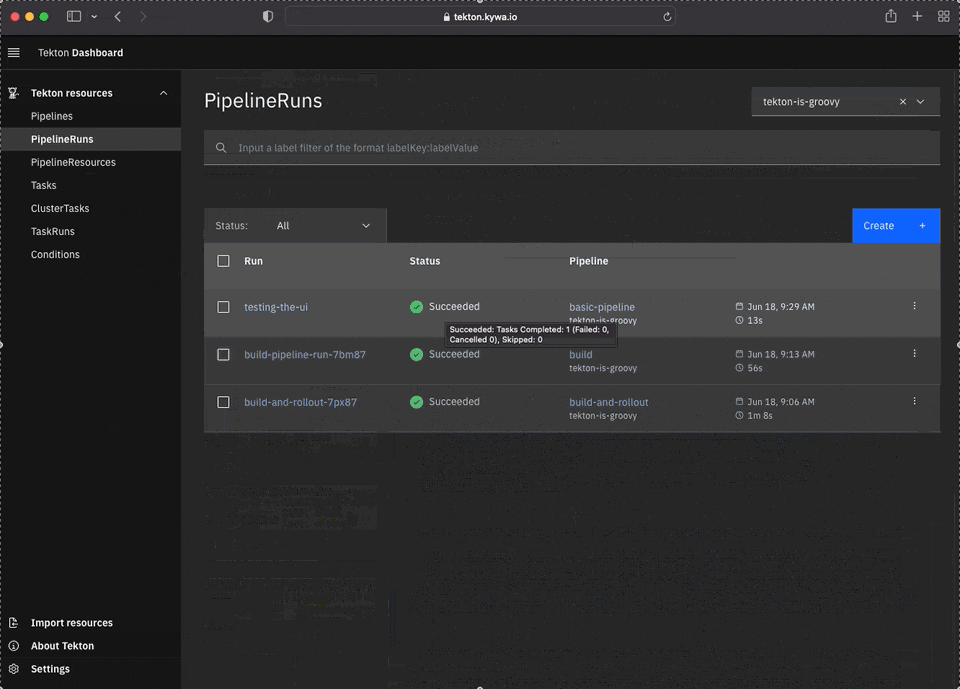
Conclusion
There are many other features of Tekton, but this guide was meant to be a light primer and get you aware of this powerful tool with its capabilities. One of the other powerful features of Tekton is Triggers (as one would expect from a CI/CD tool), but we will not be covering that in this post. I do recommend reviewing Tekton Triggers as they can really help flesh out an amazing CI/CD pipeline for your organization by enabling the running of Pipelines with events such as a Git commit being pushed into a branch among other things.
Just remember one thing, Tekton is groovy.